

What is Adaptive Time Series ML and why is it so much faster?
What is Adaptive Time Series ML and why is it so much faster?
Why we ended up building an Adaptive ML engine for Time Series


Machine learning on Time Series is an extremely difficult task: accuracy of these models is not even comparable to the successful language and vision models everyone is hyped about. Although there is no magical solution, there is a battle-tested way to enhance the real-world effectiveness of your models: allowing them to adapt as new data comes in!

Only if you could simulate how your models performed in the past with similar conditions, can you make sure that your expectations and models are realistic and valid. Otherwise, the models might underperform in production overall and at critical points and you will be almost certainly disappointed.
We’ve been on a long, unfruitful journey searching for a tool that could effectively simulate the deployment of time series models on past data. Current implementations are either not doing what you expect them to (see section) or unbearably slow (see section).
So, we built an engine (@dream-faster/fold) to make it accessible: it comes with an order of magnitude speedup, while being more ergonomic. Fold allows us to move from the limited usefulness of traditional Time Series modelling to Adaptive Machine Learning.
Why are Time Series ML models disappointing today?
Concept drift and regime changes are inherent features of most Complex Dynamical Systems influenced by society (all the time series worth modelling). They pose a serious challenge when training models:
“How do we deal with having multiple, different regimes in the time series data?”
We don't accidentally want to check our model’s performance on a single or a just a handful of regimes!
“How do we simulate how the model could have performed in production, when re-trained at regular intervals?”
My targets’ behaviour is never stationary, and we need our models to adapt to the new regimes!
“How do we deal with the cold start problem: having too little historical data?”
Could we turn the vast majority of the data (80-90%) into out-of-sample test set(s)?

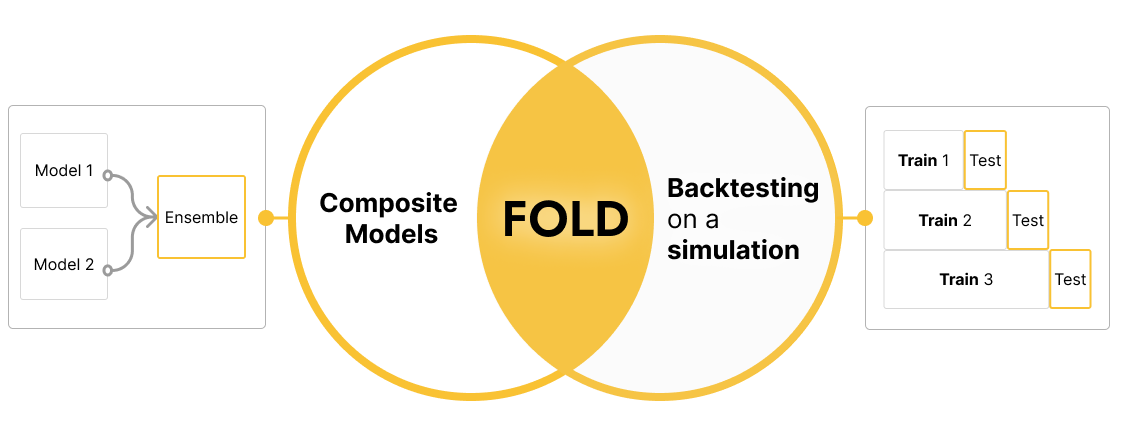
While simulating the real-world, historical deployment of your model, you leverage the temporal structure of your data: split it into many parts (folds), and train multiple models as you “walk forward” in time, on historical data.
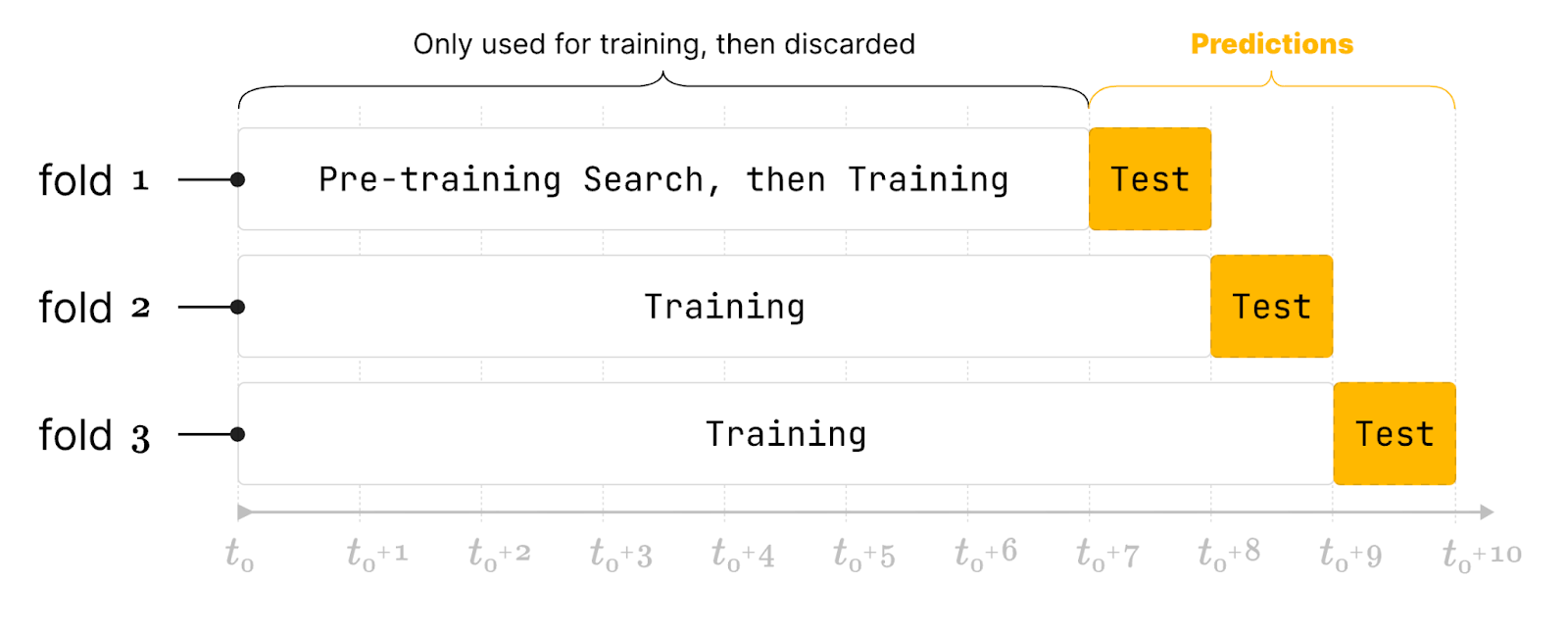
You can guarantee that these models have not seen the future, and evaluate how they would have performed in the past.
That's nice in theory, what is it like in practice?
If you have tried to do backtesting with today’s popular Python libraries, you were probably surprised: they don’t do what you expect.
These are the predictions of a simple ARIMA(1,1,0) model - returned by SKTime’s cross validation function - plotted against the target:
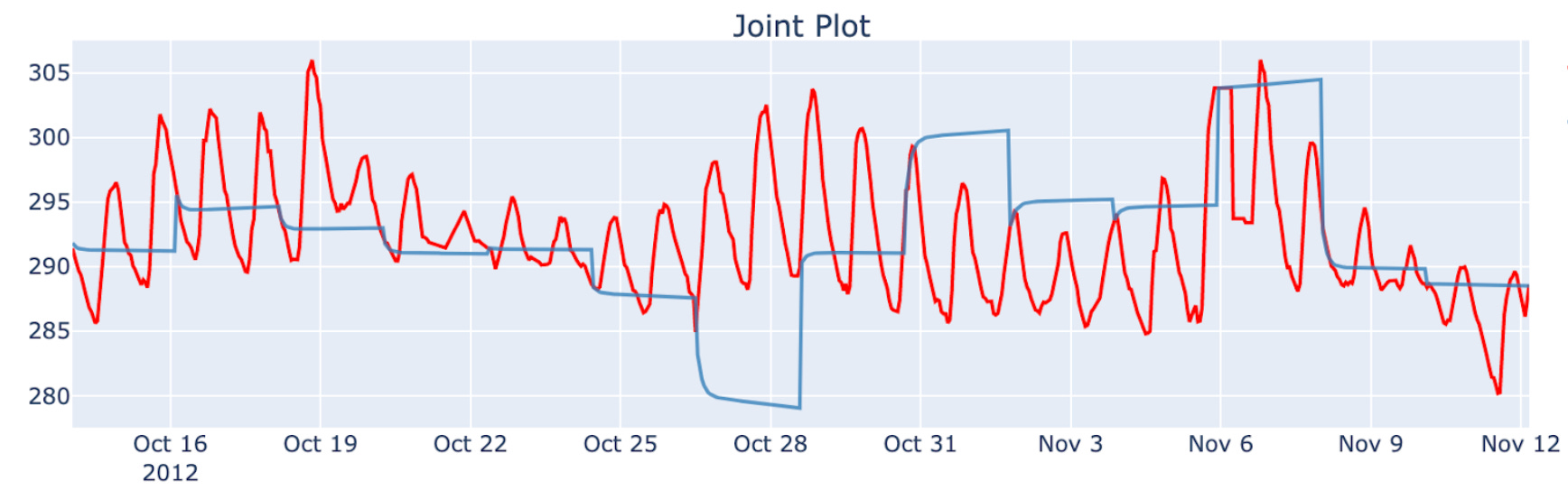
Something looks wrong: the model is not updated within a window - essentially repeating the last value for the next 100 timestamps. It doesn’t have access to the latest reading, it is static. Let’s explore what we can do about it - you will see that overcoming this problem was impossible within reasonable computational complexity before.
Introducing Adaptive ML and Adaptive backtesting
You could make your models adapt to new data within a test window, on each timestamp:
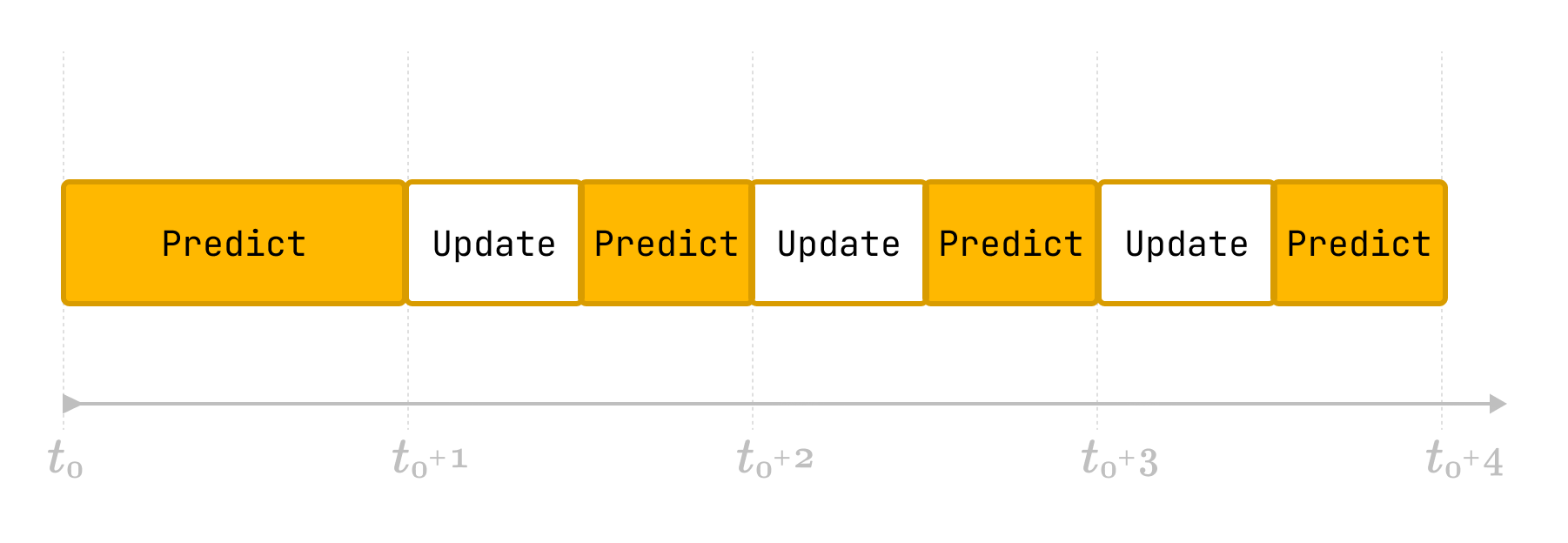
Practically, it’s the way to simulate live deployment of your models (periodically re-trained), on past data. (Technically speaking Adaptive backtesting is “Time Series Cross Validation with continuously retrained models”.)
With our library fold (github), a simple ARIMA(1,1,0) will predict:
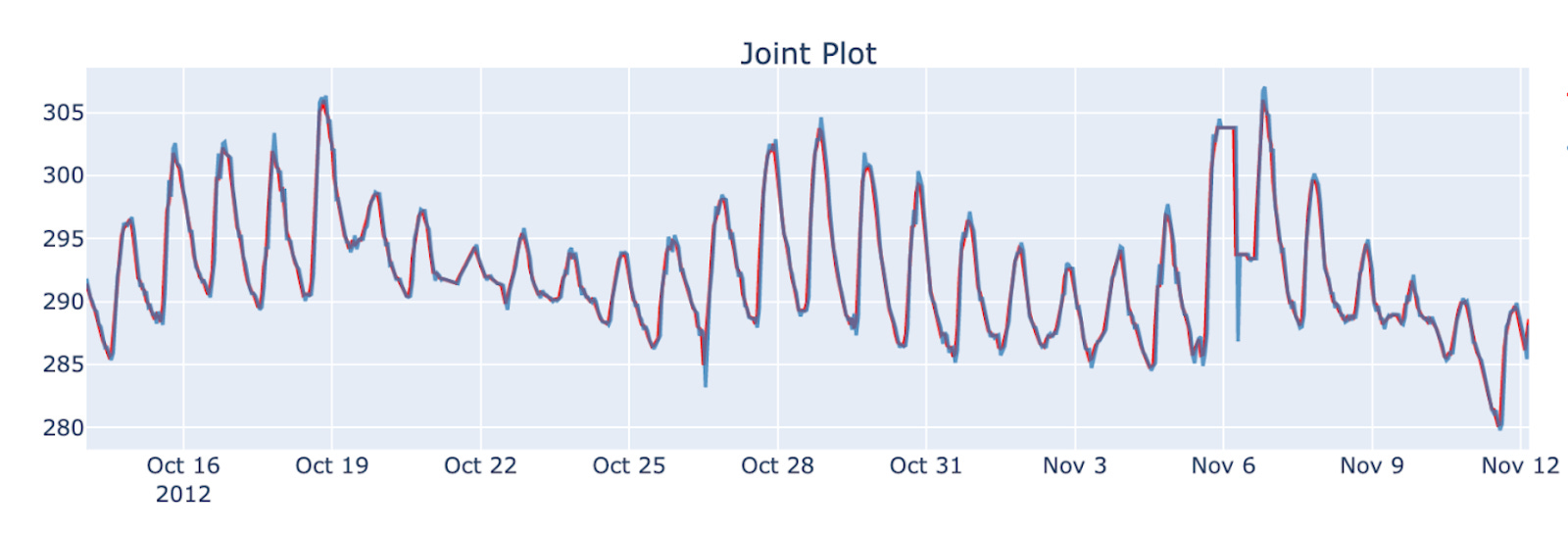
y, blue line is the prediction: preds of the ARIMA(1,1,0) modelinstead of the previously shown:
sktime (long-fh)Why create a new engine, can I not use an existing library?
You can also try setting the gap between the windows to 1, with SKTime (or other time series libraries), but then you are essentially training a new model for every timestamp.
Why? The vast majority of models can not be updated in existing time series libraries, which will make this task endlessly slow.
We can quantify “endlessly slow” for you:
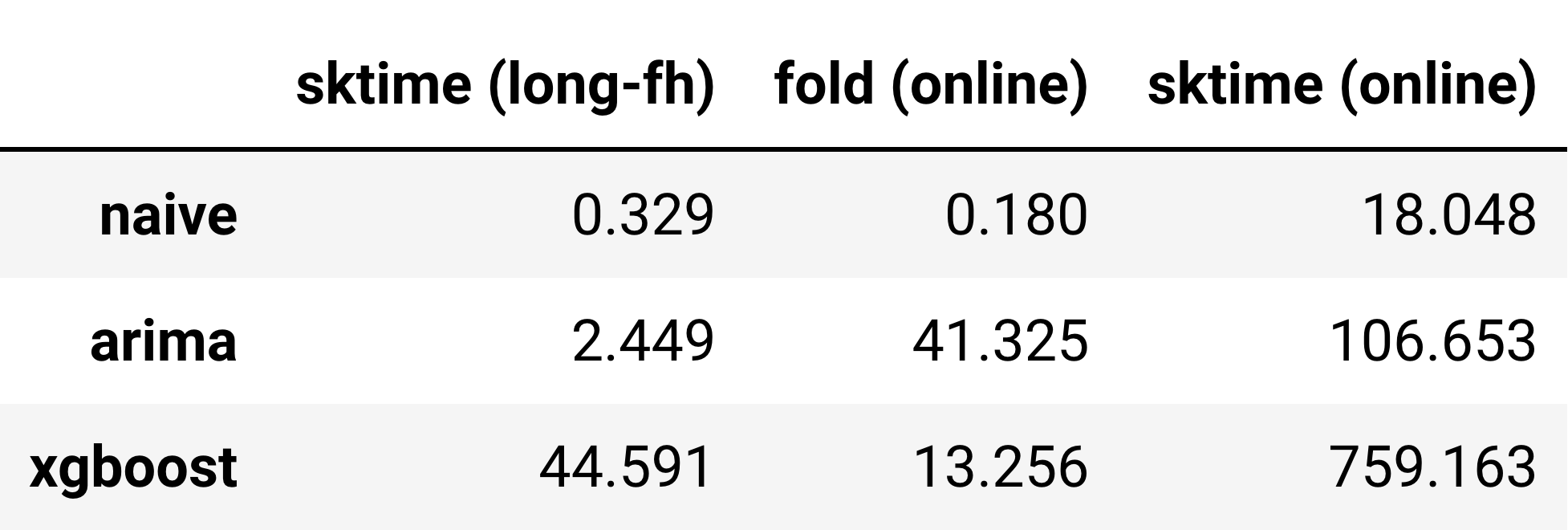
sample_size=1000. Time differences increase with sample size. Note that sktime(long-fh) gives incomparable results, as shown in Figure 6 (imprecise predictions).Check out this notebook for an in-depth comparison:
Evaluating Time Series model performance should be fast, easy and accessible.
Speed is an enabler in science. Discovering the additive attribute of logarithms created the opportunity for sailors to discover unexplored lands and for astrologers to calculate the empirical precision of untested theories.
Simulating the historical performance of Adaptive models is essential for our work, but available tools were so slow, they were essentially unusable.
This is where fold comes into the picture.
It builds on top of other great libraries: for example you can throw in a StatsForecast model with an XGBoost and ensemble them, leveraging the advantages of both. Check out the expanding list of models we support here.
How are we achieving the speed-up?
We parallelize as much as possible. Install
ray(optionally), and use all cores on your laptop or deploy to a cluster.We have a way of updating our own, online models in a mini-batch fashion during backtesting. The model parameters stay the same, but we’ll give them access to the last timestamp(s). This means you can - on
20,000 samples, using10 folds- evaluate a baseline model in under 3 seconds, and a tabular model model in less than a minute.
We also understand that usability comes first, so with fold:
There’s no need to specify a pipeline object, just throw in your models as a list
You can use the familiar scikit-learn-esque API
Easily extended with arbitrary transformations (just pass in a lambda function) and models (supports a wide range of time series and tabular ML models)
You can build arbitrarily complex pipelines
Check out Fold on GitHub. You can find a Technical Walkthrough in the docs or on colab.
We are on a mission to improve everyone’s forecasting ability
We believe there is a need for an open-core, transparent software suite for the time series domain, that allows you to make informed decisions about which time series models are appropriate for your use case.

At Dream Faster, we’re building:
A lightweight, model-independent Evaluation library of Time Series predictions that tracks metrics over time (@dream-faster/krisi).
Time Series AutoML without lookahead bias, to get accurate simulated performance on past data that you can rely on.
Re-implementation of new and classic time series models, providing an additional order of magnitude speedup during backtesting (while supporting online updates when deployed).
Training models on multiple time series at the same time, with synchronized Adaptive Backtesting!
Full support for Uncertainty Quantification, making it an internal part of Fold.
And many more…
In the meantime, we’re building a sustainable business to support our efforts. We will continue supporting research with our open core tools, but we’ll charge for production usage. We are structuring Dream Faster to forego the traditional VC blitzscaling phase and focus on providing value, while sustainably growing.
Please, have fun with it and give us feedback!
In addition, follow our newsletter for an upcoming post on why Ensemble models matter: