

Zen and the Art of Generalisation
Zen and the Art of Generalisation
Is it enough to report performance on a single dataset?


Innovation in Machine Learning is centred around new model architectures, like AlexNet or Transformers. Researchers conventionally publish the performance of these model architectures on a single dataset, even in the realm of multi-functional foundational models. Does the practice of single dataset performance hold up to scrutiny? Should “Which dataset to report on?” be a standard question to ask?
While building our latest hate speech detection project, we saw many state-of-the-art models that weren’t capable of detecting clear instances of hate speech. This led us down the path of challenging the conventional train/ test/val split approach, and evaluating models across different datasets’ test split - our expectation was that they’ll perform worse. Will that reflect reality?
A specific case: hate speech detection
Imagine yourself in the shoes of a person who hates pillows. You hate pillows so much that you’ll want to post your opinion on Reddit. You start with the title: “Pillows are shit”. But, you’re a smart person, you understand that there are models that’ll flag that post immediately, and your precious opinion will never get to see the light of the day. So, you re-phrase your title as “I love people who say: I hate Pillows”. Much better, right? No model will figure that out!
The possibilities of gaming the system are endless: you can add a widely understood negative word that’s used positively in certain contexts, use sarcasm, misspell a word, etc.1
Hate speech is an adversarial game of moderators on one side and people with malicious intent on a public forum.This is confirmed by the numbers as well: if you look at the scores on PapersWithCode, hate speech detection is lagging behind other benchmarks.
Something is suspicious…
Empirical Risk Minimization, the convention common in Machine Learning dictates that we sample random data points from our dataset, that we’ll not use for training, only for evaluation. In theory, we can’t do any better, as we don’t know the underlying distribution of the real world data. So we choose the path that minimizes the risk of picking the wrong distribution - we use randomness.
Sounds fine! But, what’s the result of that in our specific case: hate speech detection? Let’s manually check some examples that’d smash the hate speech barometer, but are mis-classified on otherwise top performing models:
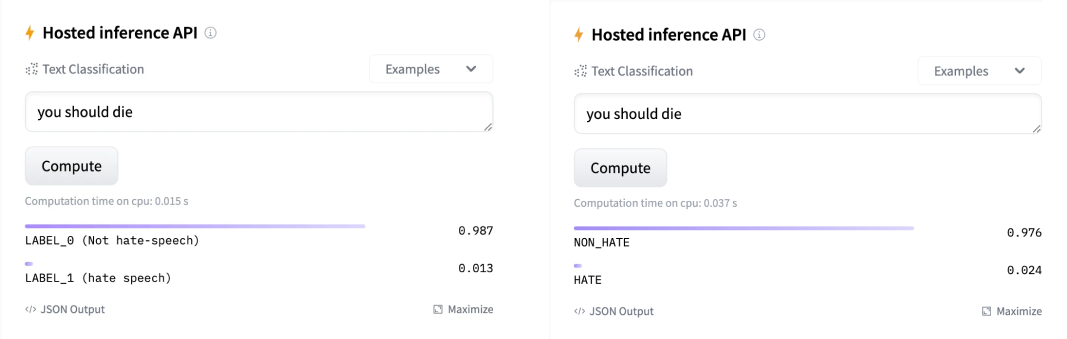
This is how we started on doubting whether we can “trust” that any of the reported metrics reflect true generalization capability, or, is it just overfitting in disguise.
Experimentation setup
We set up 144 experiments to see the impact on generalization performance (f1 macro metric) of various models and the datasets they were trained on. These experiments were a permutation of five different models, three different training sets and four different test sets.
Two statistical models to dip into the cutting-edge (a TF-IDF-based SKLearn ensemble and a Transformer-architecture), one symbolic model that isn’t trained (Vader) and three baseline models in order to see how completely naive models behave (flagging everything or nothing as hate speech, and one that randomly chooses).
We first trained all models on three different training sets - TweetEval, DynaHate and a merged concatenation of the two (without over or under sampling) - then tested them on four different test splits - TweetEval, DynaHate, HateCheck and the equal sample combination of all test splits (with oversampling to equal their size). Below you see a table summarising key statistics about each dataset:
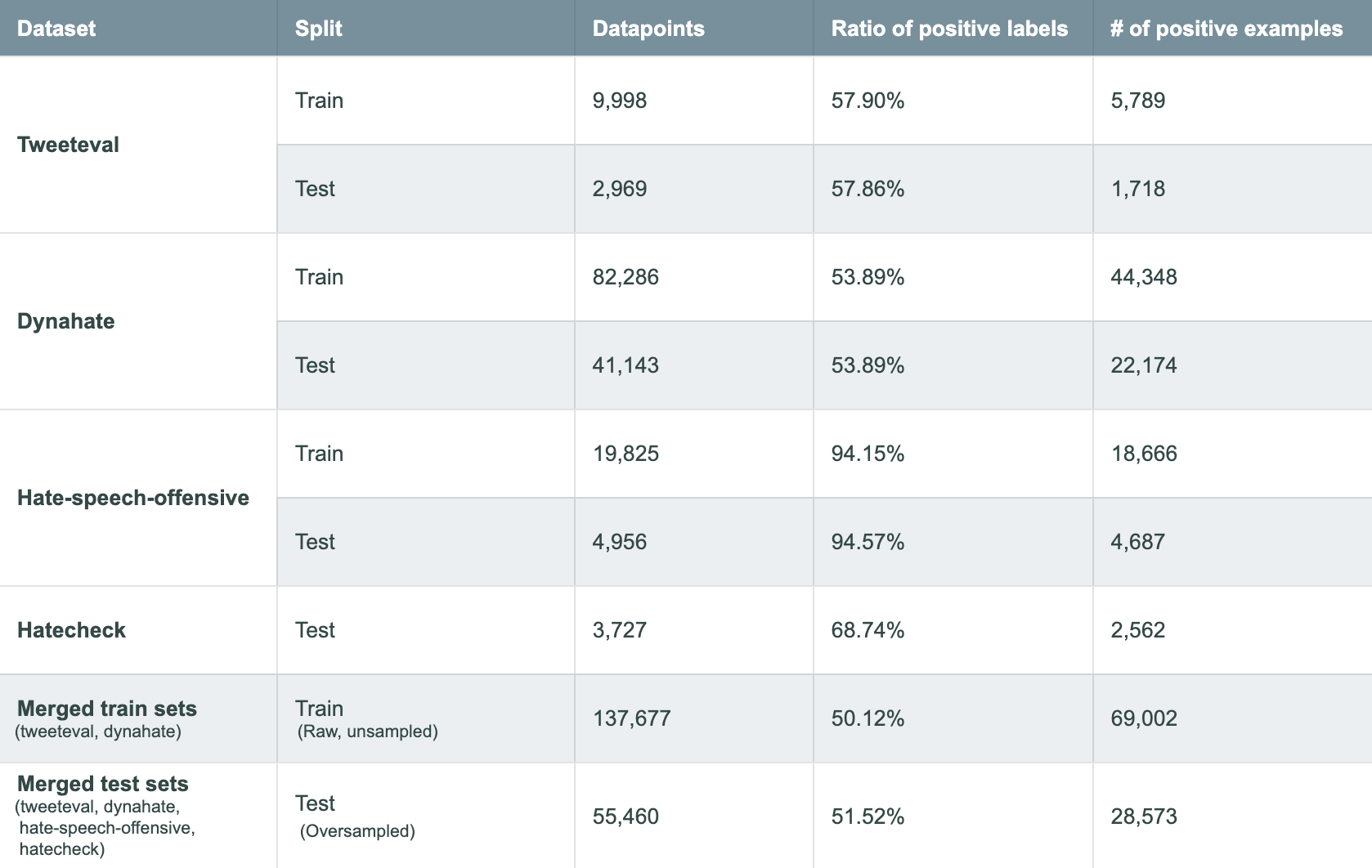
As both the TweetEval and the DynaHate paper used f1 macro score to report their results, we focused on that as well.
Raw observations we notice
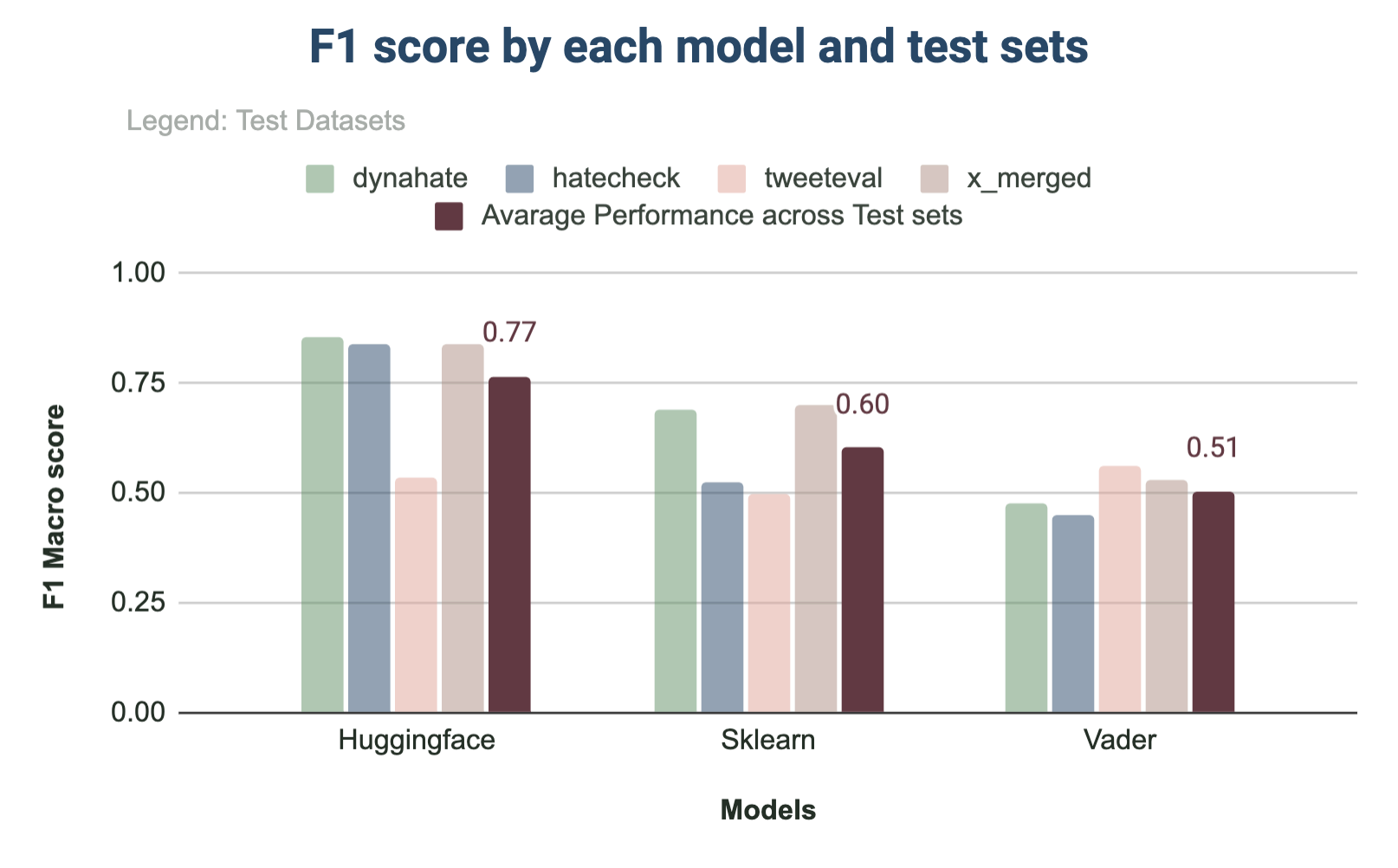
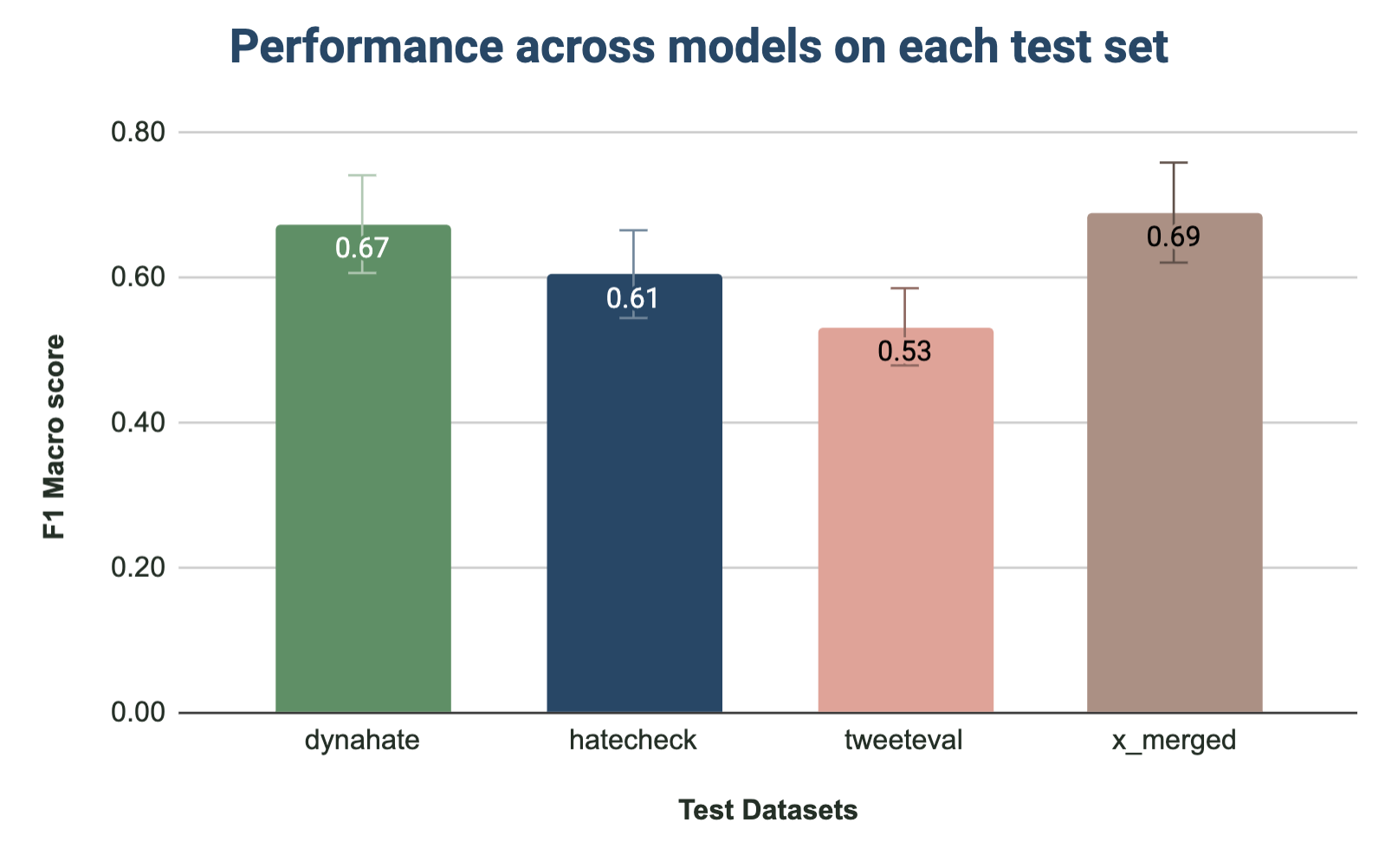
Interestingly, when it came to what dataset we were training on, the results were clear: as shown in Figure 3 all models performed the best when trained on DynaHate. Training on DynaHate outperformed training on TweetEval, even when we tested on TweetEval’s test split.
The merged training dataset consists of both the TweetEval and DynaHate dataset and is unsampled, so it is unsurprising that it performed similarly to the larger DynaHate training set.
There could be a number of reasons: It is possible that DynaHate has more inherent signal which models can learn, such as keywords strongly associated with hate speech; or the quality of labels is substantially better than at TweetEval: fewer mislabeled instances.

As seen in Figure 4 the performance by model types confirmed the trend: our Huggingface Transformer model performed the best for all test datasets, with Sklearn coming in second. Surprisingly, the Vader model outperformed both the Transformer model and Sklearn model in the case of TweetEval.
How would we interpret the results?
Surprisingly, we don’t see a clear performance degradation when we test on a different dataset’s test split.
There’s two clear takeaways:
The more data we train on, the better the results are. Training on TweetEval (10k samples) is clearly inferior to training on DynaHate (80k samples).
Choice of model matters. A larger, more complex model (Transformers) outperforms the less sophisticated counterpart (TF-IDF+SKLearn) in almost all cases.
But, there are many different factors that could define how well training on a dataset will perform / generalize, that are hard to define in a quantitative manner without a huge amount of time investment: for example overall difficulty (what’s the distribution of easy-to-classify vs hard-to-classify samples?) or quality (what’s the ratio of mislabeled samples?).
Nevertheless, there is idiosyncratic risk (if you don’t mind an analogy from finance) in only testing new, novel model architectures. There is variance in our single dataset test/evaluation data that we can’t attribute to much rather than noise.
Discussion
The datasets we use are sampled from and representing a subset of our reality. The catch is: there’s always an assumption baked into the sampling process, at least when the task is to classify rare events. You can’t simply take 1000 posts from social media and give it to a human label it up - more than 99% of it will not be classified as hate speech. Which means it’ll be really expensive to collect enough positive samples to publish a dataset, and those samples may not include obvious instances that the platform has already caught before publishing.
It is not in your best interest to rely on a single author’s assumption on how to sample the data: you want to hedge your bets, and diversify. Especially, since your novel new architecture may be sensitive to that assumption and may result in overfitting to the idiosyncratic attributes of the chosen dataset - and may not actually generalize that well to the problem you’re actually trying to solve.
A single dataset introduces a diversifiable risk that researchers can mitigate by either reporting performance on multiple datasets, or, by merging datasets from the same domain (both their train / test splits, separately).
Fortunately, with the advance of larger, “foundational” models, we are more incentivised to report metrics on a variety of benchmarks - but there are still thousands of research papers on model innovation, published with a single benchmark.
Even without malintent language is so nuanced that a single word or letter can change the meaning of sentences. If you love pillows you might have said instead: Pillows are the shit.