

The dark side of Graph Neural Networks
The dark side of Graph Neural Networks
The current limitations of Graph Neural Networks


In part 1, How I Learned to Stop Worrying and Love Graphs, we talked about how graphs are the most universal representation of almost any data and benefit from several advantageous properties.

Does that mean we can disregard Computer Vision (CV) and Natural Language Processing (NLP), convert all images or text to graphs and have one “Master Algorithm” learn on all kinds of data?
Not so fast. CV/NLP is a collection of domain-specific techniques that make it easier for ML algorithms to learn on highly structured, use-case-specific data. Let’s see where the dominant Graph Neural Network (GNN) architectures, Message Passing Neural Networks currently fall short.
Graphs are powerful, but GNNs don’t always excel
GNNs are hard to parallelise
There are sequential steps during message passing1, so they’ll never be as fast as Convolutional Neural Networks or Transformers, which removed the need for recurrence and therefore can batch process lots of data up concurrently. This can not be overstated - Deep Learning is enjoying its heyday because it has won the Hardware Lottery, and old architectures that can’t be made embarrassingly parallel easily are sinking into oblivion faster than I can finish this sentence.
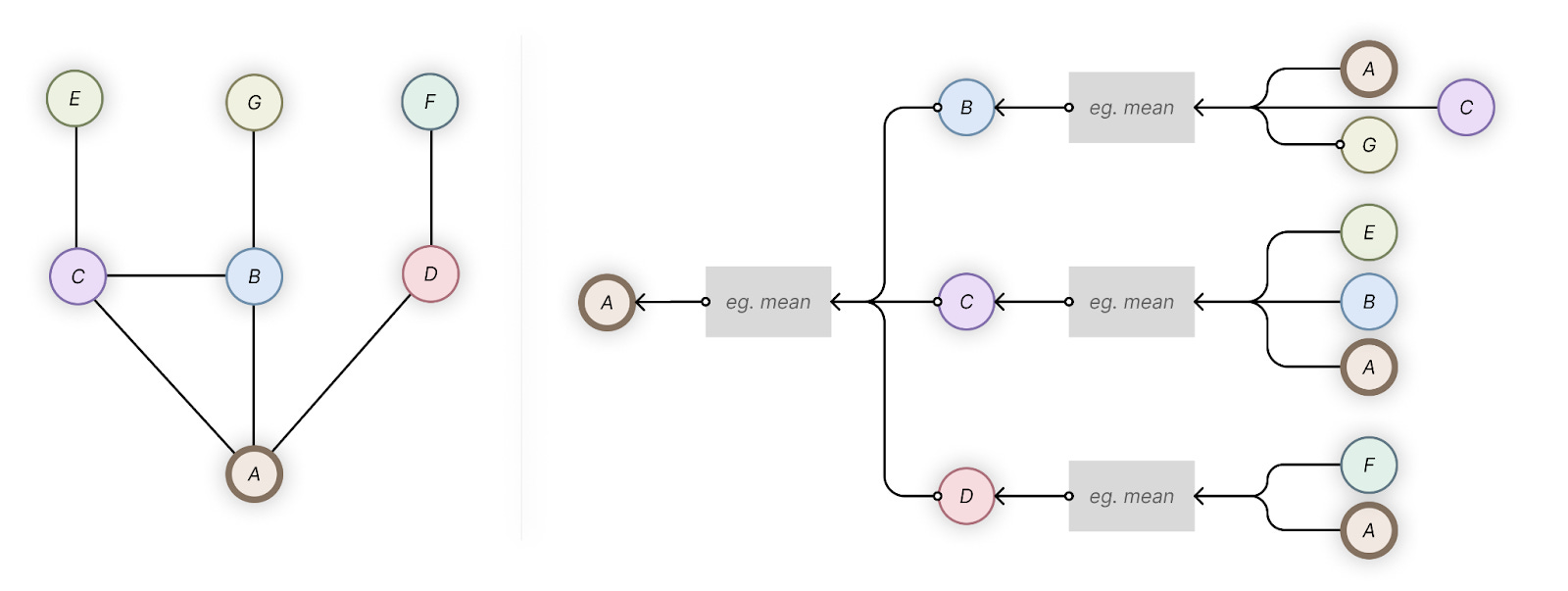
GNNs introduce computational complexity
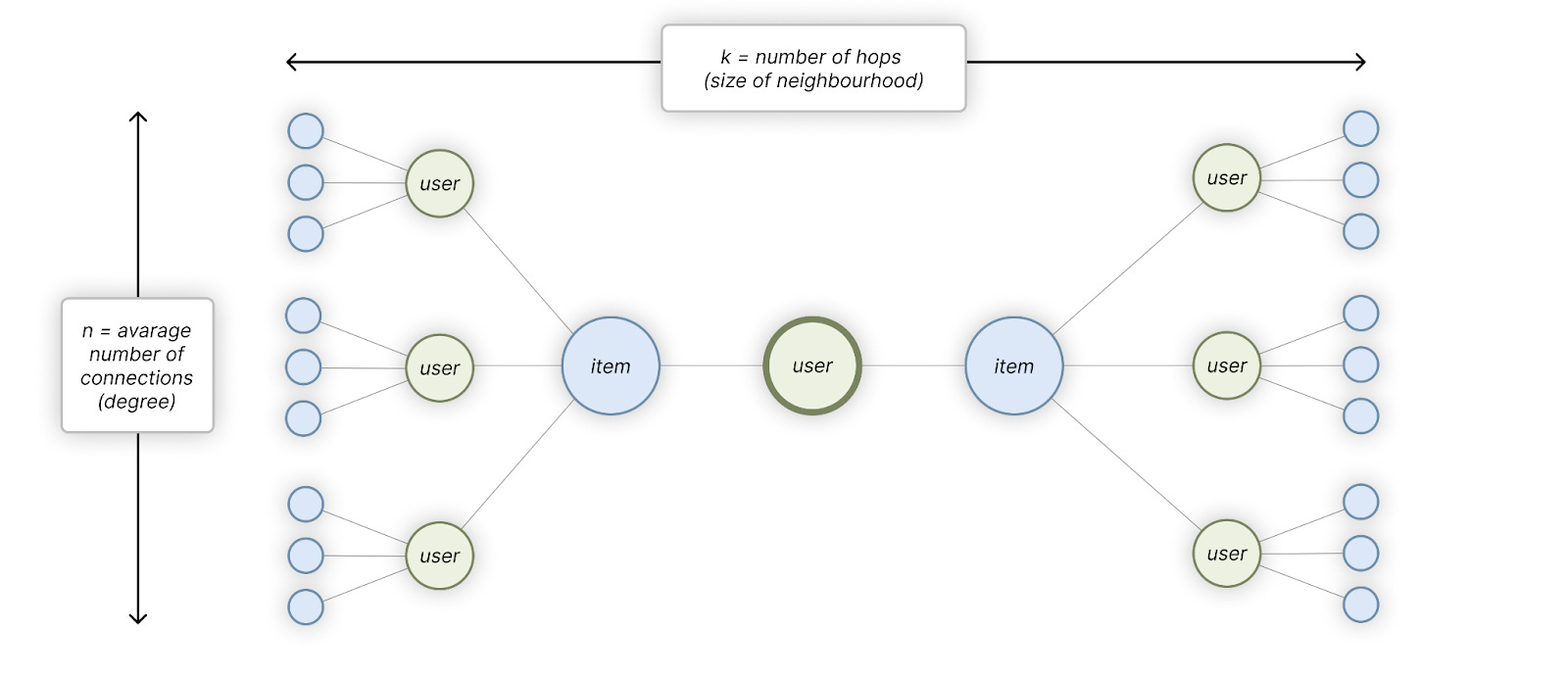
The compute needed to do message passing blows up quickly with the size of the graph: we end up with kⁿ neighbours to aggregate for each node (where k is the average degree and n is the number of neighbours to hop on). In practice, this is mitigated by sampling a fixed number of neighbours on each level - but that both limits the information that can be aggregated and brings stochasticity into the mix, none of you may actually want!
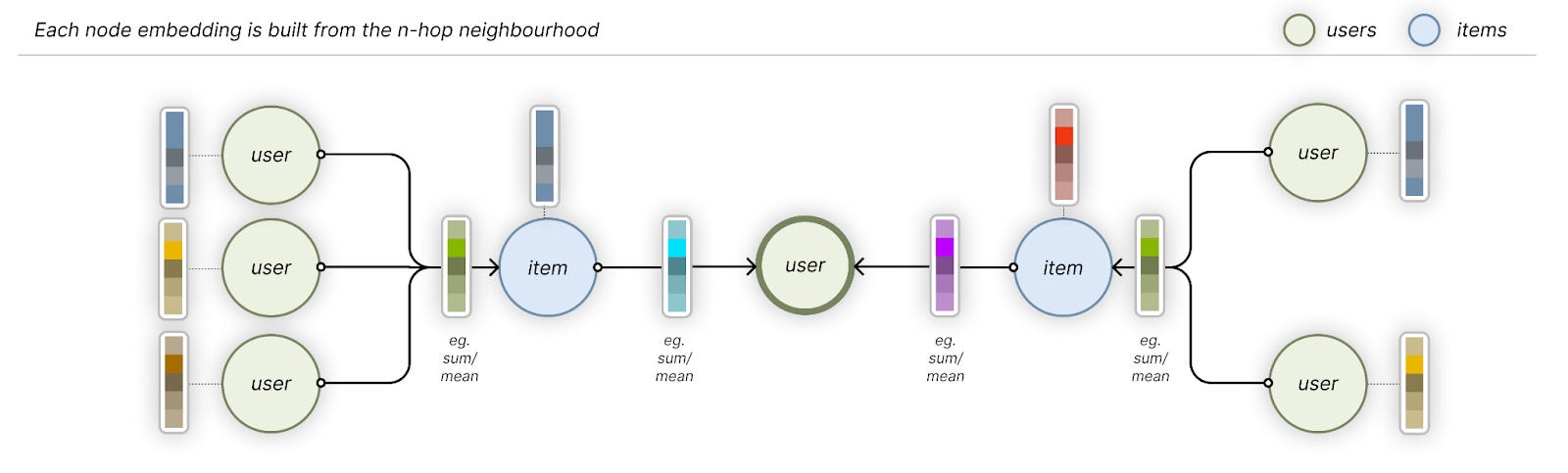
Most of this computation is often not useful: summing or taking an average in the aggregation step, as well as the required pooling step, mean a lot of the specific information gets smoothed out.
All while pretraining doesn’t work yet
It looks like the otherwise widespread practice of pre-training has yet to be successfully applied to GNNs (we can only guess why this is the case).
Nevertheless, until we see large-scale pre-training emerge in the respective field of application, GNNs will start their learning journey with random weights - a massive disadvantage compared to, let’s say, word embeddings in NLP, models of unthinkable amounts of data. There’s even an argument that we confused the success of the Transformers architecture with the successful practice of pre-training.
Discrete features are blurred together
During message passing the target node’s representation is derived from the aggregated features of the neighbourhood, thereby “blurring the boundary” between discrete nodes into regional representations. This may not matter when you want to treat similar customers the same way but could be an issue with fundamentally discrete entities, like types of atoms. That could rather result in a hilarious or fatal mistake.
This is demonstrated in “How Powerful are Graph Neural Networks?” - there are certain, simple structures that a GNN can’t distinguish from each other.
Limits on the model size
The smoothing issue also creates a hard limit on how many GNN layers you can have at your disposal. The more n-hop neighbours you’re the model is aggregating information from, the more smooth each node’s final embedding will be - if you don’t pay attention, and aggregate all the information from a huge graph, all of your node embeddings will look very, very similar. This is called oversmoothing, and in practice limits you to a practical maximum of 3-4 GNN layers.
All the above often result in poor performance
In many use cases, GNNs don’t necessarily outperform simpler methods.
You could replace millions of trained parameters with six, and you get better results than a full-blown GNN.
In other cases, the simplest form of a Graph Convolutional Network outperforms more complex ones, such as learning molecule features with what the authors call single-layer GCN – Quantum Deep Fields. Does the additional complexity introduced by the graph format superfluous?
We may need a new architecture to resolve these problems.
What could come next?
So despite all of this convincing, are we here to just declare defeat?
Although there are some shortcomings with the current approaches, Graph Neural Networks are used in production by large companies, especially where the core of their data is a graph, like social networks. As a standout example, Jure Leskovec lead Pinterest in developing its PinSAGE architecture.
Some current unresolved are:
Could we find enough commonalities between graphs to create foundational models, which could be used for transfer learning?
Is there a way to shortcut message passing, thereby making it easily parallelizable?
Is it possible to preserve local features of nodes while keeping the invariant nature of message passing?
Can universal data structures, like graphs ever replace their specialized (and optimized) counterparts? Or does their universality mean they’ll never outperform a custom-tailored approach?
In a separate post, we discuss the engineering realities of ML on Graphs, and our experience of blood and sweat with a Kaggle competition.
Each hop in the neighbourhood calculates the features on each previous-hop