

How I Learned to Stop Worrying and Love Graphs
How I Learned to Stop Worrying and Love Graphs
Why Machine Learning on Graphs could be the future of AI


Twitter is buzzing about Large Language Models (LLMs), and many researchers are doubling down on further scaling models like GPT-3 on an ever bigger corpus of text.
Regardless if you subscribe to this or not, is text, a single-dimensional sequence of words the best representation to use when modelling all the complexity of our reality?
Couldn’t we do better, by connecting related concepts to words, and encoding meaningful extra information into those relationships? Our hunch says yes and fortunately, this can be easily achieved with graphs and Graph Neural Networks (GNNs)!
Why get enthusiastic about Graph Neural Networks?
Reading this post we’ll familiarise you with the advantages of graphs as a data structure, why it can be useful to run ML algorithms on graphs and finally give a glimpse into a way we can inject human expert knowledge into Machine Learning systems. More specifically we’ll go through these points:
A powerful data representation: Graphs are universal, compact, interpretable and permutation invariant
Machine Learning on Graphs allows us to learn both local and global features when using graphs and to inject human knowledge into our system. However, there are shortcomings.
Graphs are the universal representation of (any) data
As categorisation of the world into buckets is considered a fundamental cognitive capability of humans, it is no surprise that modelling the world as graphs is straightforward and universal: graphs are made out of buckets (nodes) connected by relationships (edges).
Let’s look at a few examples of digital data and demonstrate how each could be modelled as a graph.
A sequence of text? Just a homogenous graph connected sequentially to each neighbour1

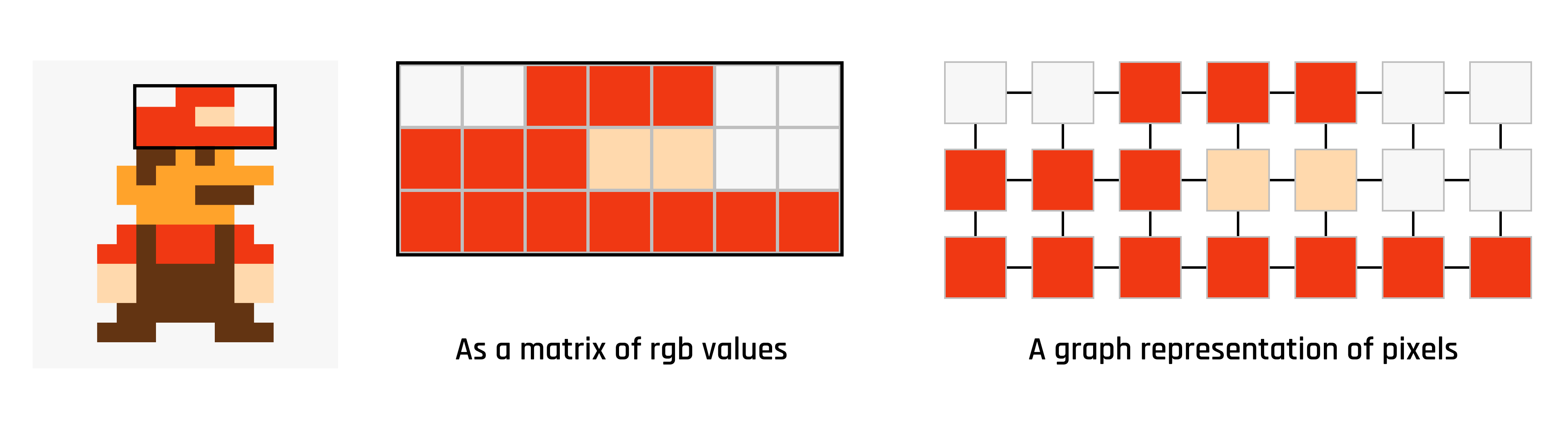
An image? Simply a highly structured, regular graph where each pixel is connected to only its direct neighbour:
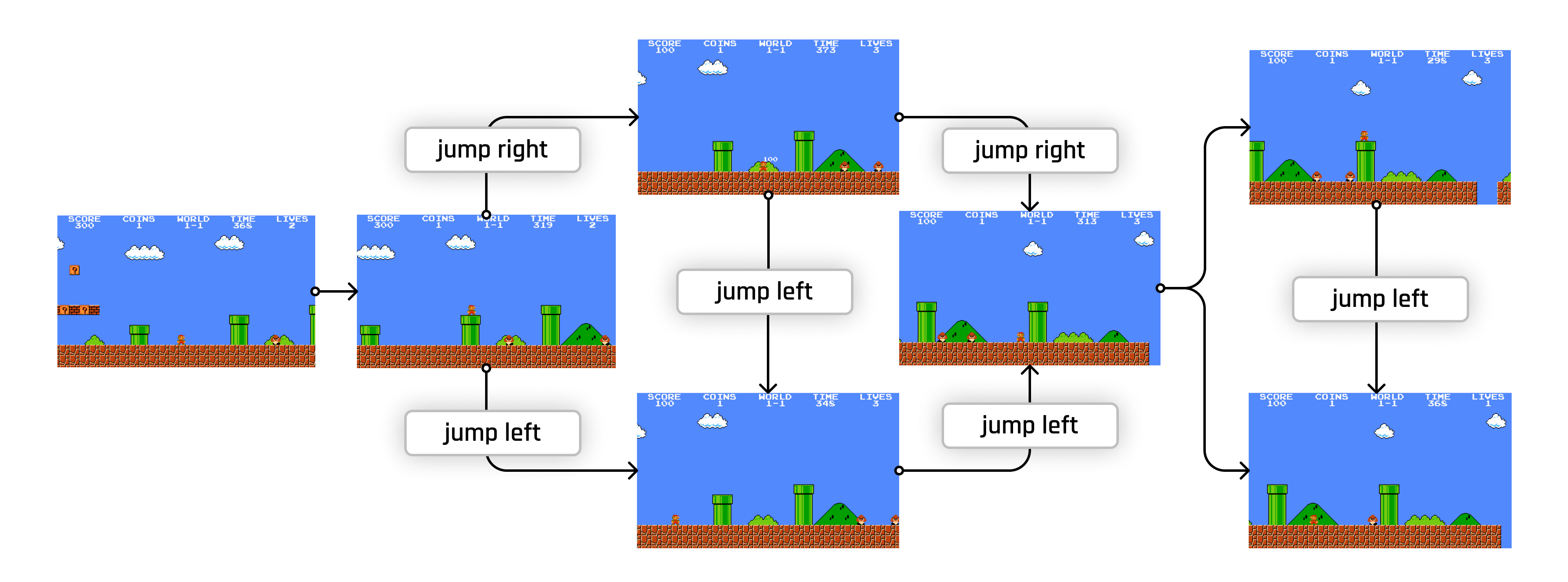
A game, like Super Mario? It has various graph representations eg.:
the underlying Abstract Syntax Tree (AST) compiled from the source code,
the Dataflow Graph is derived from the AST.
On a more Reinforcement Learning level, we could consider the game of Super Mario as a Markov Decision Process, each node in the graph representing a unique state of the game, connected by actions that lead to that state.
Graphs are compact and interpretable
Graphs excel when it comes to compactness. Since nodes can be connected, their content doesn’t need to be duplicated, only referenced as a relationship (edge).
Another essential aspect is interpretability. Because nodes can only be discrete entities (with clear boundaries), they’re considered a localist representation - if you need to edit one, you’ll only need to do it in one place. The opposite of that is a distributed representation (for example, word embeddings), where the information is scattered among many different axes/dimensions, where humans will have a hard time interpreting its meaning, as well as editing it.
Graphs are permutation invariant
Imagine using a highly connected data structure that you store in a tabular, or text format: you start enumerating the connections from a starting node, then follow with the neighbours’ connections... Then, when you need to do this all over again, you pick a different starting node and… the data you’ll get in the end will be potentially very different from your previous try!
So you realize that a single graph can be displayed/stored in many different ways:
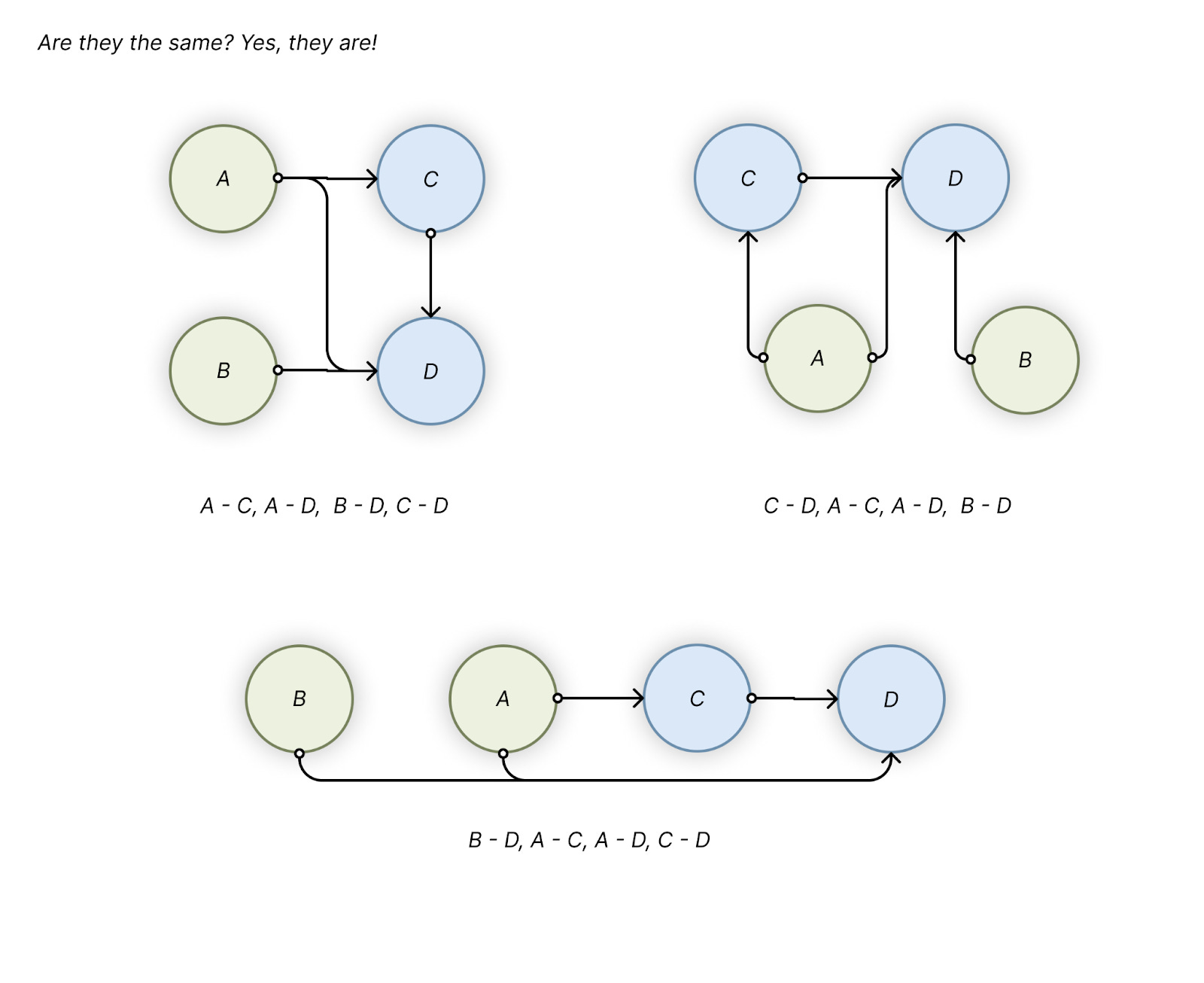
But, ultimately, you’ll want one single “permutation invariant” representation, that encompasses all the different ways you can describe your data - and that’s what you get if you stick to the graph representation. There are ways you can avoid “flattening of the graph” - using relational or graph databases, or specialized file formats.
You’d think some type of data is especially poorly modelled without graphs: like molecules. But, currently, the most popular method to represent a molecule is SMILES, which flattens the graph into a 1-dimensional sequence, that’s permutation equivariant (you have many potential representations for the same molecule). This is usually counteracted by some hacks life-science ML libraries had to implement. We have a long way to go!
You can learn both local and global features when using graphs
Not only are they universal, but very often they are also a more information-dense representation. Take this example – you have a list of transactions:
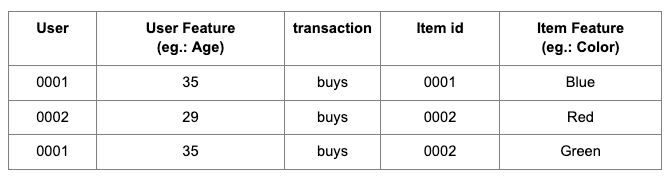
If you feed these transactions into a tabular Deep Learning architecture, it’ll embed each User (Color, Item, etc). into a high-dimensional vector space, in a way that similar users (Colors, etc.) will be close to each other. Graph Neural Networks will also fundamentally do the same, but the way those node embeddings are created are different: GNNs will aggregate the information and patterns that neighbouring nodes and their relationships hold.
With tabular ML, you store each user’s position in high-dimensional space in the embeddings dictionary. With GNNs, you only store the (weights of the) layers that’ll extract the node embeddings when you feed the (sub-)graph through the network. This results in a more dynamic system that can be more updated as new data flows in.
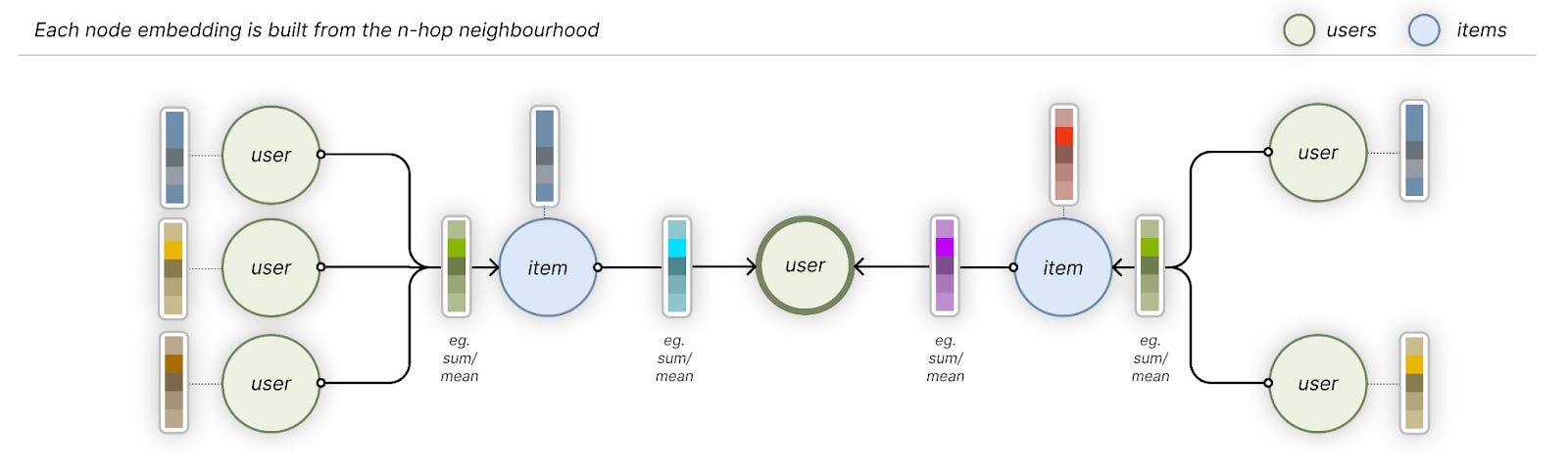
This may look like a subtle difference, but it may be very important when you have a new User you want to add and create embeddings for. GNNs can quickly create a vector representation out of the new User, by only accessing its 3-4 hop neighbours. With tabular Deep Learning, you’d need to add a new User’s id into the embedding dictionary and run it through the (probably) whole dataset to accurately place the new entry close to other similar Users.
In the end, the most frequently used GNNs learn local patterns (with respect to a node’s neighbours), similarly to what Convolutional Neural Network architectures are doing on images - and they’re also appropriately called Convolutional GNNs. They’re not the only game in town, but probably the only one that can be efficiently deployed, as of today.
But GNNs don’t have to rely exclusively only on local representations and pattern matching. There are also ways of integrating multiple levels of abstractions into the same graph. If it is useful to also understand the global properties of the graph when looking at a node - just add a meta-node that connects that to each type of node.
Graphs can help inject human knowledge into the data
Imagine you know that a certain feature (“winter”, as a “season”) is very important in your dataset: if all you got is a graph, you can connect all the customers who purchased anything in the winter, by creating a new “Winter” node.
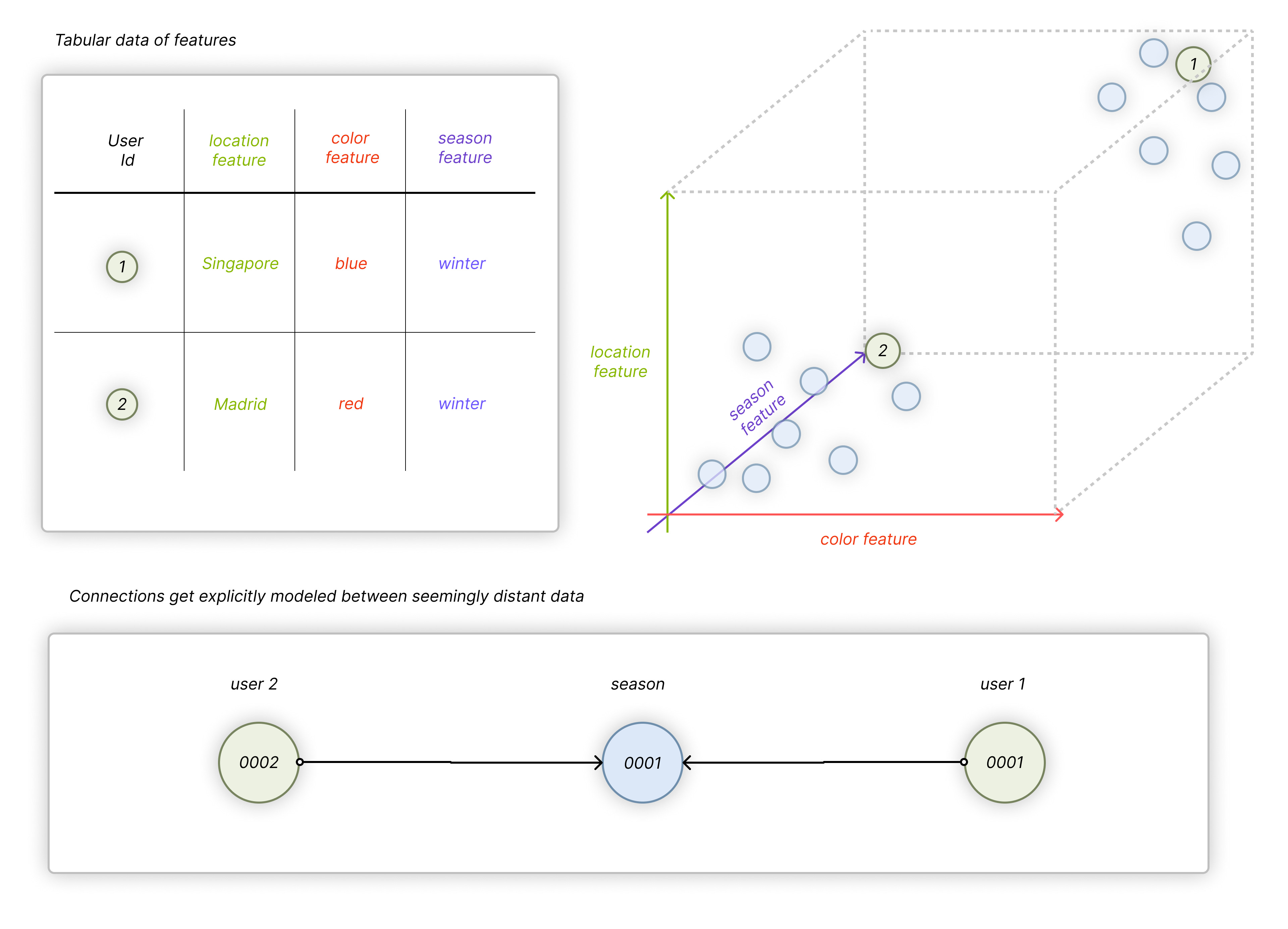
This way, in the case of GNNs, the “Winter” node will contain a lot of latent information about all the users who also purchased something during the winter, and any of those users can use this to their advantage.
Guiding the ML algorithm about what’s important is important when you want to deploy your models (and not just evaluate them on benchmarks). Also, it is really hard to achieve with the current approaches, using unstructured data (like text), where you can’t point out causal relationships.
Where GNNs need to improve
As we demonstrated, there are many reasons graphs allow for a richer and more flexible representation of our world. Furthermore, we showed that Machine Learning on graphs, specifically Graph Convolutional Networks could allow human experts and automatic machine learning systems to interact.
However, there is a dark side to Graph Neural Networks. Want to learn about the current shortcomings, opportunities and our struggles in deploying them? Subscribe to read our next post!
Although one can create more sophisticated versions with words/nodes being fully interconnected - which is what the attention mechanism mines.